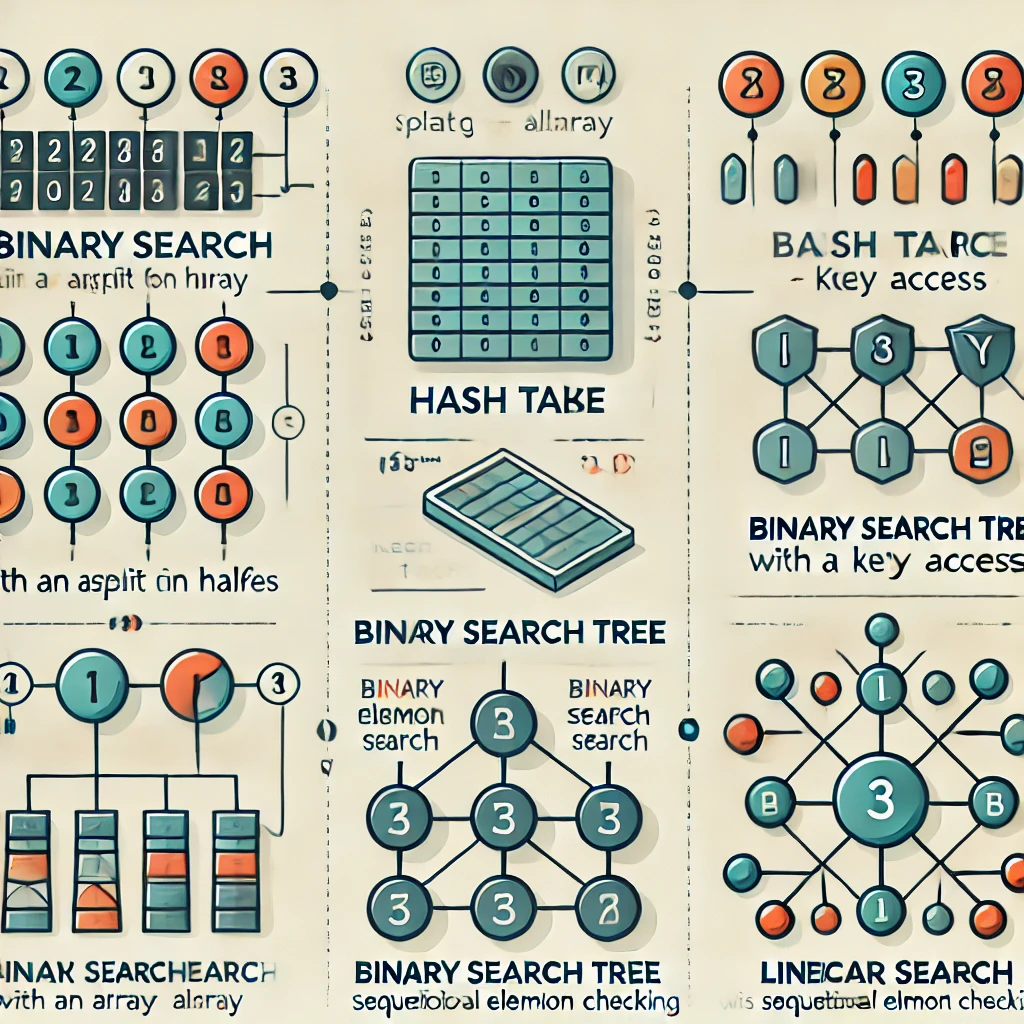
Найкращий алгоритм пошуку елемента у великому масиві даних залежить від структури даних та їх організації. Ось кілька найбільш ефективних алгоритмів для різних типів масивів:
1. Бінарний пошук (Binary Search) 🔍
Коли використовувати: Якщо масив відсортований.
- Часова складність: O(log n)
- Опис: Алгоритм поділяє масив на дві частини, порівнюючи шуканий елемент із середнім елементом масиву. Якщо елемент менший, пошук продовжується в лівій частині, якщо більший — у правій.
- Перевага: Дуже ефективний на відсортованих масивах. Працює значно швидше за лінійний пошук для великих даних.
2. Пошук у хеш-таблиці (Hash Table) 🧮
Коли використовувати: Якщо важлива швидкість і доступ до елементів за ключем.
- Часова складність: O(1) (в середньому), O(n) (у найгіршому випадку)
- Опис: Хеш-таблиця використовує функцію хешування, щоб швидко знаходити елементи за унікальним ключем.
- Перевага: Дуже швидкий доступ до елементів, якщо хеш-функція добре збалансована. Ідеально підходить для великих масивів даних, де потрібно часто виконувати пошук.
3. Пошук за допомогою дерева пошуку (Binary Search Tree, B-tree) 🌳
Коли використовувати: Якщо дані потребують частого додавання/видалення.
- Часова складність: O(log n)
- Опис: Бінарне дерево пошуку або B-дерево дозволяють швидкий пошук у впорядкованих структурах, де кожен вузол має два або більше дочірніх вузлів.
- Перевага: Динамічне додавання та видалення елементів без необхідності переміщення всього масиву.
4. Індексовані пошуки (Indexed Search) 📚
Коли використовувати: Якщо масив занадто великий, і необхідно оптимізувати пошук за допомогою індексації.
- Часова складність: O(1) (для пошуку за індексом)
- Опис: Індексація дозволяє організувати дані таким чином, щоб швидко переходити до потрібної області масиву.
- Перевага: Особливо корисно для баз даних і пошуку у великих наборах даних, де дані розбиті на блоки.
5. Пошук методом поділу і завоювання (Divide and Conquer) ⚔️
Коли використовувати: Для великих і складних структур даних.
- Часова складність: Залежить від реалізації (наприклад, для Merge Sort — O(n log n))
- Опис: Поділ масиву на менші підмасиви і виконання пошуку в кожному з них із наступним об’єднанням результатів.
- Перевага: Ефективний при обробці великих даних із паралельною обробкою частин масиву.
6. Лінійний пошук (Linear Search) 📏
Коли використовувати: Для неструктурованих даних.
- Часова складність: O(n)
- Опис: Простий пошук, при якому кожен елемент перевіряється послідовно до знаходження шуканого.
- Перевага: Підходить для невідсортованих масивів і маленьких наборів даних, але малоефективний для великих масивів.
Висновок
Для відсортованих великих масивів найкращим вибором буде бінарний пошук. Якщо ж масив не відсортований, ефективно використовувати хеш-таблиці або дерева пошуку. Вибір алгоритму залежить від конкретної задачі, доступної пам’яті та часу виконання.